OPV2V
An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle CommunicationWhat is OPV2V?
OPV2V is the first large-scale Open Dataset for Perception with V2V communication. By utilizing a cooperative driving co-simulation framework named OpenCDA and CARLA simulator, we collect divergent scenes with various numbers of connected vehicles to cover challenging driving situations like severe occlusions.
Key Features:
- aggregated sensor data from multi-connected automated vehicles
- 73 scenes, 6 road types, 9 cities
- 12K frames of LiDAR point clouds and RGB camera images, 230K annotated 3D bounding box
- comprehensive benchmark with 4 LiDAR detectors and 4 different fusion strategies (16 models in total)



Diverse Scenes

Suburb Midblock

Urban T-intersection

Urban Curvy Road

Freeway Entrance Ramp

Urban 4-way Intersection

Rural Curvy Road
Sensor Suites
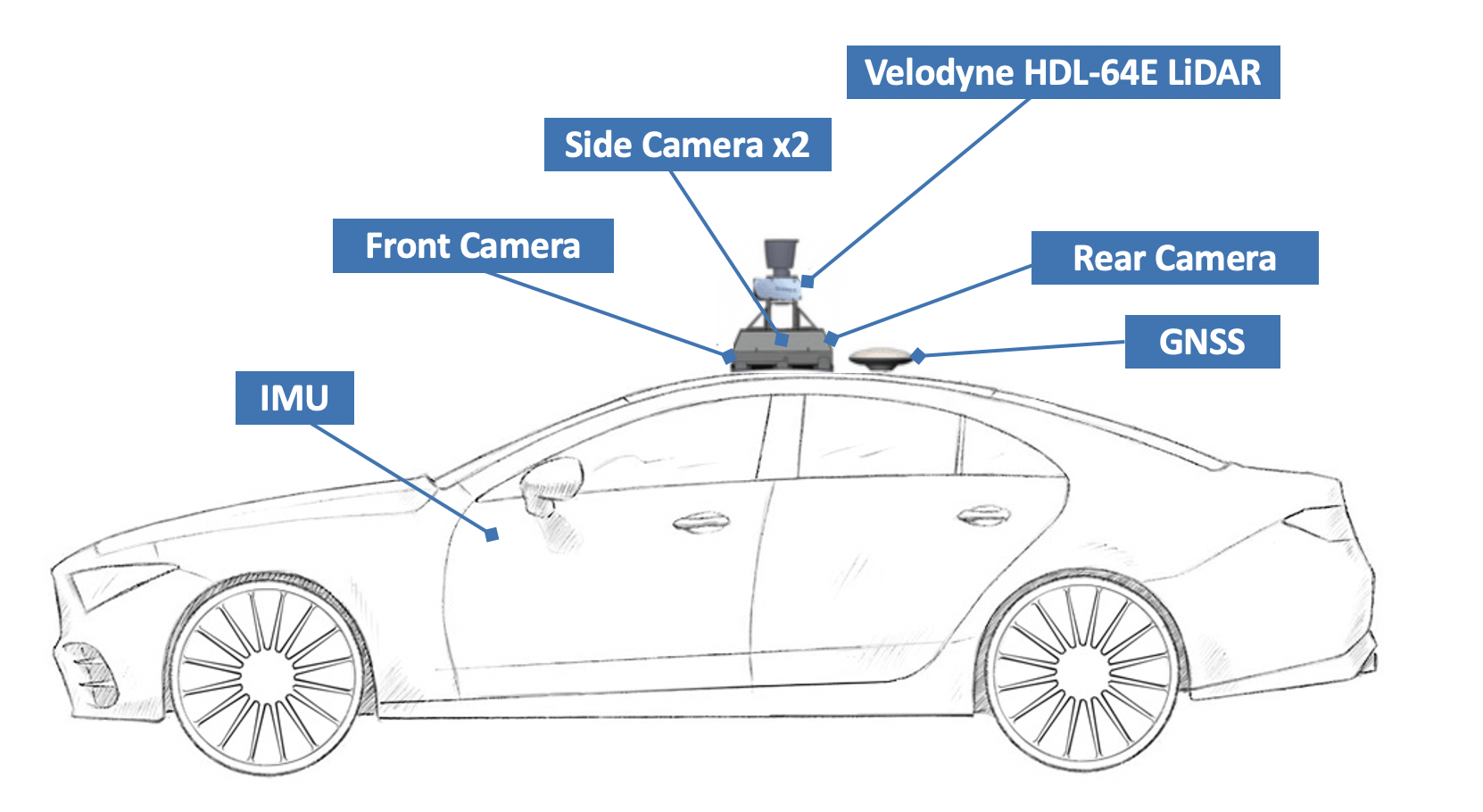
- Lidar: 120 m detection range, 130,0000 points per second, 26.8◦ vertical
- 4x Camera: 110 ◦ FOV, 800×600 resolution
- GNSS: 0.2m error
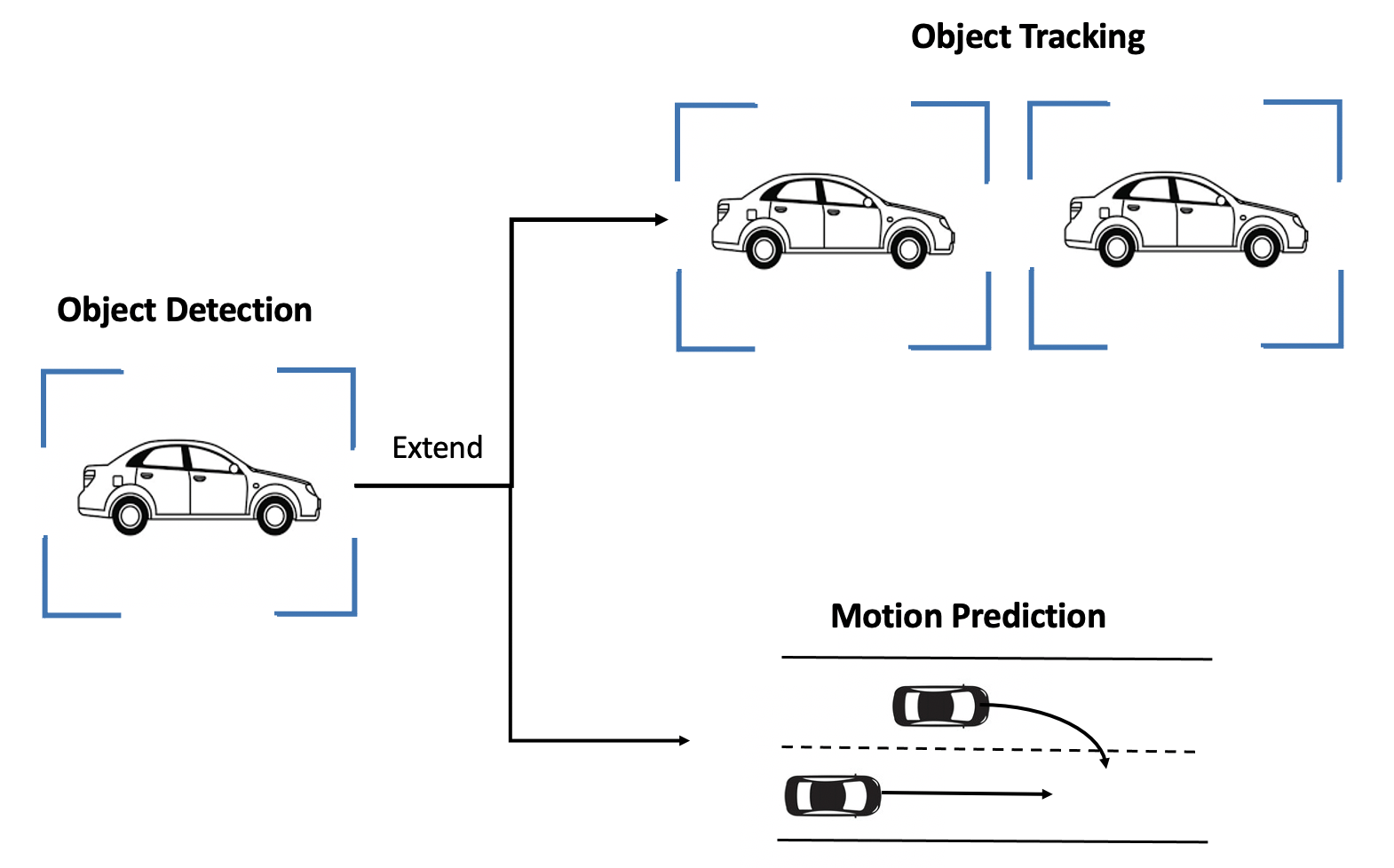
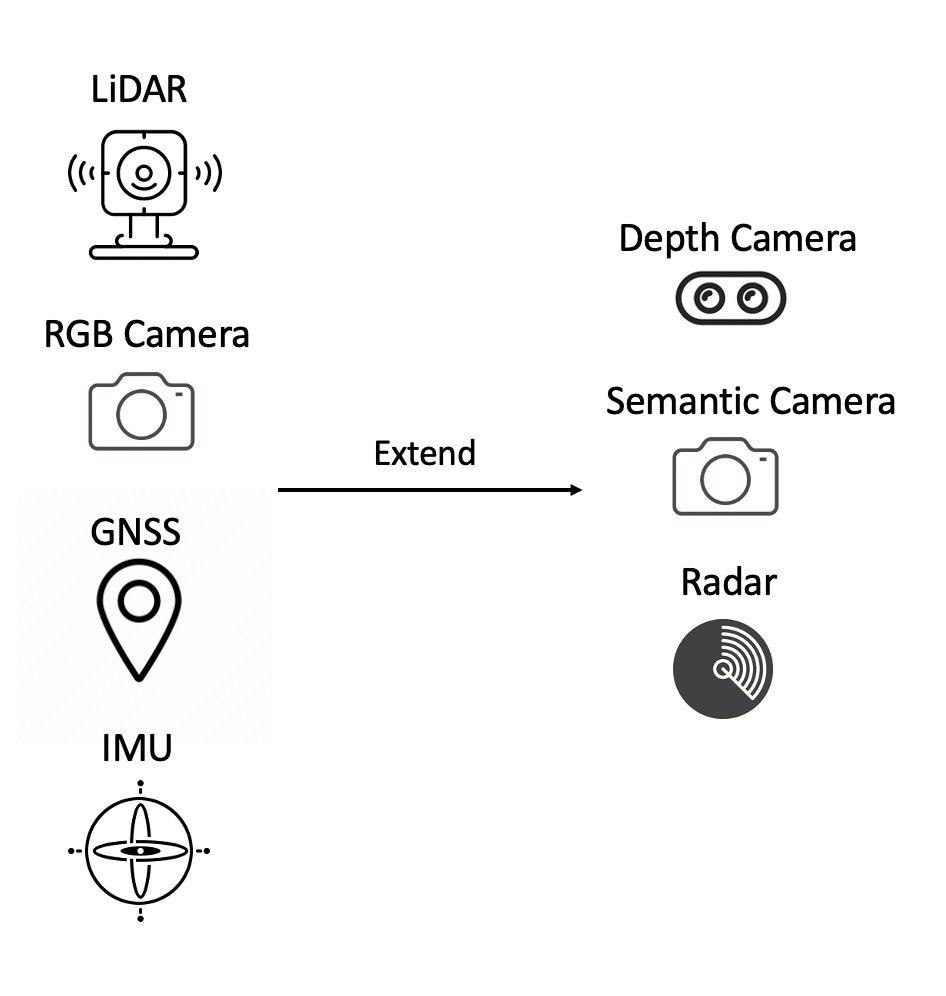
Extensible and Reproducible
OPV2V is highly reproducible and extensible. With the support of a popular simulation tool OpenCDA, we are able to save the configuration file that includes the random seeds for each generated scene. Within these configuration files, researchers can easily extend the original data with new devices like depth cameras and new tasks like motion prediction with identical driving environments.
Benchmark
4 LiDAR detectors, 4 fusion strategies, a total of 16 models for benchmarking.
On top of that, we propose an Attentive Fusion Pipeline that operates on the local graph, which achieves the best performance and still preserves high accuracy even after 4096x compression rate. Check our paper for more details.